RetinaGAN: An Object-aware Approach to Sim-to-Real Transfer
Abstract
The success of deep reinforcement learning (RL) and imitation learning (IL) in vision-based robotic manipulation typically hinges on the expense of large scale data collection. With simulation, data to train a policy can be collected efficiently at scale, but the visual gap between sim and real makes deployment in the real world difficult. We introduce RetinaGAN, a generative adversarial network (GAN) approach to adapt simulated images to realistic ones with object-detection consistency. RetinaGAN is trained in an unsupervised manner without task loss dependencies, and preserves general object structure and texture in adapted images. We evaluate our method on three real world tasks: grasping, pushing, and door opening. RetinaGAN improves upon the performance of prior sim-to-real methods for RL-based object instance grasping and continues to be effective even in the limited data regime. When applied to a pushing task in a similar visual domain, RetinaGAN demonstrates transfer with no additional real data requirements. We also show our method bridges the visual gap for a novel door opening task using imitation learning in a new visual domain.
Video
I. Introduction
Vision-based reinforcement learning and imitation learning methods incorporating deep neural network structure can express complex behaviors, and they solve robotics manipulation tasks in an end-to-end fashion

Some of this data collection effort can be mitigated by collecting these required episodes in simulation and applying sim-to-real transfer methods. Simulation provides a safe, controlled platform for policy training and development with known ground truth labels. Such simulated data can be cheaply scaled. However, directly executing such a policy in the real world typically performs poorly, even if the simulation configuration is carefully controlled, because of visual and physical differences between the domains known as the reality gap. In practice, we find the visual difference to be the bottleneck in our learning algorithms and focus further discussion solely on this.
One strategy to overcome the visual reality gap is pixel-level domain adaptation; such methods may employ generative adversarial networks to translate the synthetic images to the real world domain
To address this, we propose RetinaGAN, a domain adaptation technique which requires strong object semantic awareness through an object detection consistency loss. RetinaGAN involves a CycleGAN
RetinaGAN is a general approach to adaptation which provides reliable sim-to-real transfer for tasks in diverse visual environments (Fig. 1). In a specific scenario, we show how RetinaGAN may be reused for a novel pushing task. We evaluate the performance of our method on three real world robotics tasks and demonstrate the following:
-
RetinaGAN, when trained on robotic grasping data, allows for grasping RL task models that outperform prior sim-to-real methods on real world grasping by 12%.
-
With limited (5-10%) data, our method continues to work effectively for grasping, only suffering a 14% drop in performance.
-
The RetinaGAN trained with grasping data may be reused for another similar task, 3D object pushing, without any additional real data. It achieves 90% success.
-
We train RetinaGAN for a door opening imitation learning task in a drastically different environment, and we introduce an Ensemble-RetinaGAN method that adds more visual diversity to achieve 97% success rate.
-
We utilize the same pre-trained object detector in all experiments.
II. Related Work
To address the visual sim-to-reality gap, prior work commonly apply domain randomization and domain adaptation techniques.
With domain randomization, a policy is trained with randomized simulation parameters and scene configurations which produce differences in visual appearance
Domain adaptation bridges the reality gap by directly resolving differences between the domains
Action Image
Among prior work that apply semantic consistency to GAN training, CyCADA
Recently, RL-CycleGAN
III. Preliminaries
A. Object Detection

We leverage an object detection perception model to provide object awareness for the sim-to-real CycleGAN. We train the model by mixing simulated and real world datasets which contain ground-truth bounding box labels (illustrated in Fig. 2). The real world object detection dataset includes robot images collected in general robot operation; labeling granularity is based on general object type -- all brands of soda will be part of the "can" class. Simulation data is generated with the PyBullet physics engine
Object detection models are object-aware but task-agnostic, and thus, they do not require task-specific data. We use this single detection network as a multi-domain model for all tasks, and we suspect in-domain detection training data is not crucial to the success of our method. Notably, the door opening domain is very different from the perception training data domain, and we demonstrate successful transfer in Section V-C.
We select the EfficientDet-D1
We note that it is also possible to train separate perception networks for each domain. However, this adds complexity and requires that the object sets between synthetic and real data be close to bijective, because both models would have to produce consistent predictions on perfectly paired images.
While segmentation models like Mask-RCNN
B. CycleGAN
The RetinaGAN training process builds on top of CycleGAN
IV. RetinaGAN

RetinaGAN trains with a frozen object detector, EfficientDet, that provides object consistency loss. Once trained, the RetinaGAN model adapts simulated images for training the task policy model. Similarly to CycleGAN, we use unpaired data without labels. The overall framework is described in Algorithm 1 and illustrated in Fig. 3, and the details are described below.
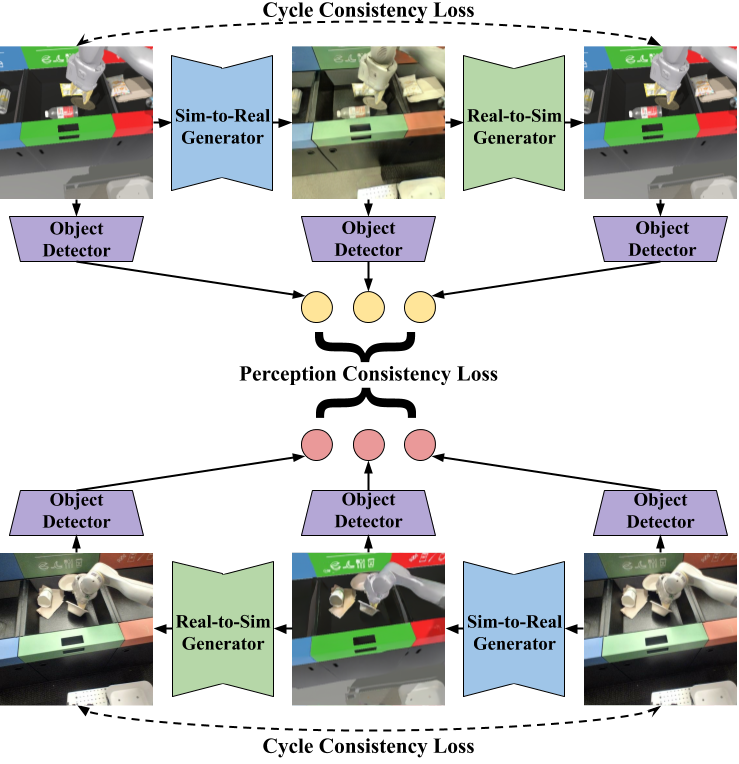
From CycleGAN, we have six images: sim, transferred sim, cycled sim, real, transferred real, and cycled real. Because of object invariance with respect to transfer, an oracle domain adapter would produce identical predictions between the former three images, as well as the latter three. To capture this invariance, we run inference using a pre-trained and frozen EfficientDet model on each image; for each of these pairs, we compute a perception consistency loss.
A. Perception Consistency Loss
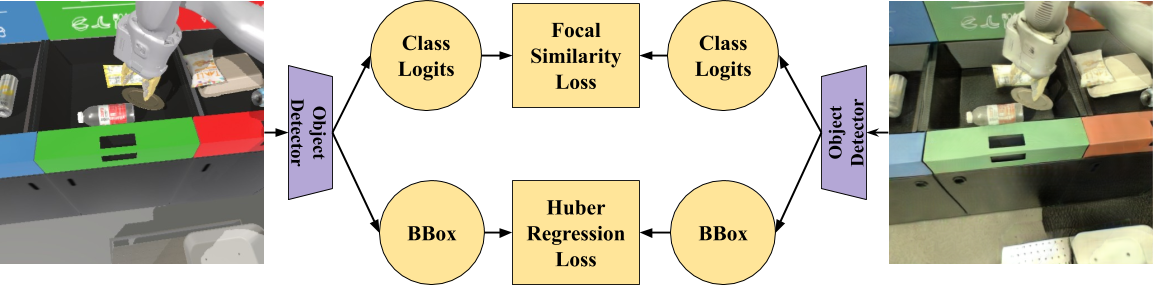
The perception consistency loss penalizes the generator for discrepancies in object detections between translations. Given an image , EfficientDet predicts a series of anchor-based bounding box regressions and class logits at several levels in its Feature Pyramid Network
We compute the perception consistency loss () given a pair of images similarly to the box and class losses in typical RetinaNet/EfficientDet training. However, because the Focal Loss
Without loss of generality, consider an image pair to be and . This loss can be computed with a pre-trained EfficientDet network as:
is the Huber Loss
The Perception Consistency Loss on a batch of simulated images and real images , using the sim-to-real generator and the real-to-sim generator , is:
We halve the losses involving the cycled and images because they are compared twice (against the orginal and transferred images), but find that this weight has little effect in practice.
We arrive at the overall RetinaGAN loss:
B. Focal Consistency Loss (FCL)
We introduce and derive a novel, interpolated version of the Focal Loss (FL) called Focal Consistency Loss (FCL), which extends support to a ground truth confidence probability from a binary . Focal losses handle class imbalances in one-stage object detectors, improving upon Cross Entropy (CE) and Balanced Cross Entropy (BCE) losses (Section 3,
We begin from CE loss, which can be defined as:
where is the predicted probability.
BCE loss handles class imbalance by including a weighting term if and if . Interpolation between these two terms yields:
Focal Loss weights BCE by a focusing factor of , where and is if and if to addresses foreground-background imbalance. FCL is derived through interpolation between the binary cases of :
FCL is equivalent to FL when the class targets are one-hot labels, but interpolates the loss for probability targets.
Finally, FL is normalized by the number of anchors assigned to ground-truth boxes (Section 4,
V. Task Policy Models and Experiments
We test the following hypotheses: 1) the value of sim-to-real at various data sizes by comparing robotics models trained with RetinaGAN vs without RetinaGAN 2) with purely sim-to-real data, how models trained with various GANs perform 3) transfer to other tasks.
We begin with training and evaluating RetinaGAN for RL grasping. We then proceed by applying the same RetinaGAN model to RL pushing and finally re-train on an IL door opening task. See the Appendix for further details on training and model architecture.
A. Reinforcement Learning: Grasping
We use the distributed reinforcement learning method Q2-Opt
When using real data, we train RetinaGAN on 135,000 off-policy real grasping episodes and the Q2-Opt task model on 211,000 real episodes. We also run a low data experiment using 10,000 real episodes for training both RetinaGAN and Q2-Opt. We run distributed simulation to generate one-half to one million on-policy training episodes for RetinaGAN and one to two million for Q2-Opt.
We evaluate with six robots and sorting stations. Two robots are positioned in front of each of the three waste bins, and a human manually selects a cup, can, or bottle to grasp. Each evaluation includes thirty grasp attempts for each class, for ninety total. By assuming each success-failure experience is an independent Bernouili trial, we can estimate the sample standard deviation as , where is the average failure rate and is the number of trials.

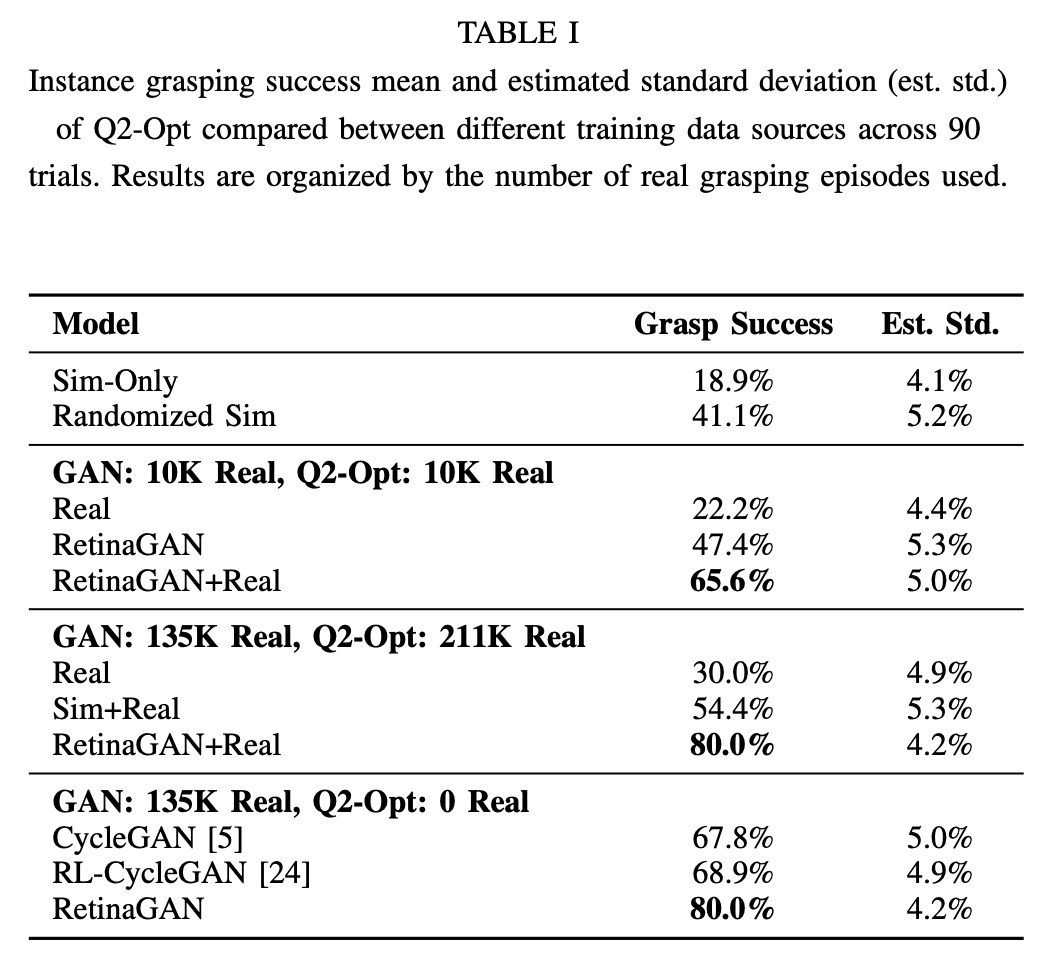
We use the RL grasping task to measure the sim-to-real gap and compare methods in the following scenarios, which are displayed in Table I:
- Train by mixing 10K real episodes with simulation to gauge data efficiency in the limited data regime.
- Train by mixing 135K+ real grapsing episodes with simulation to investigate scalability with data, data efficiency, and performance against real data baselines.
- Train Q2-Opt with only simulation-only to compare between RetinaGAN and other sim-to-real methods.
In the sim-only setup, we train with fixed light position and object textures, though we apply photometric distortions including brightness, saturation, hue, contrast, and noise. In simulation evaluation, a Q2-Opt model achieves 92% instance grasping success on cups, cans, and bottles. A performance of 18.9% on the real object equivalents indicates a significant sim-to-real gap from training in simulation alone.
We compare against baselines in domain randomization and domain adaptation techniques. Domain randomization includes variations in texture and light positioning.
On the limited 10K episode dataset, RetinaGAN+Real achieves 65.6%, showing significant performance improvement compared to Real-only. When training on the large real dataset, RetinaGAN achieves 80%, demonstrating scalability with more data. Additionally, we find that RetinaGAN+Real with 10K examples outperforms Sim+Real with 135K+ episodes, showing more than 10X data efficiency.
We proceed to compare our method with other domain adaptation methods; here, we train Q2-Opt solely on sim-to-real translated data for a clear comparison. RL-CycleGAN is trained with the same indiscriminate grasping task loss as in
B. Reinforcement Learning: 3D Object Pushing

We investigate the transfer capability of RetinaGAN within the same sorting station environment by solving a 3D object pushing task. We test the same RetinaGAN model with this visually similar but distinct robotic pushing task and show that it may be reused without fine-tuning. No additional real data is required for both the pushing task and RetinaGAN.
The pushing task trains purely in simulation, using a scene with a single bottle placed within the center bin of the sorting station and the same Q2-Opt RL framework (Fig. 6). Success is achieved when the object remains upright and is pushed to within 5 centimeters of the goal location indicated by a red marker. We stack the initial image (with the goal marker) and current RGB image as input. For both sim and real world evaluation, the robot needs to push a randomly placed tea bottle to a target location in the bin without knocking it over. Further details are described in
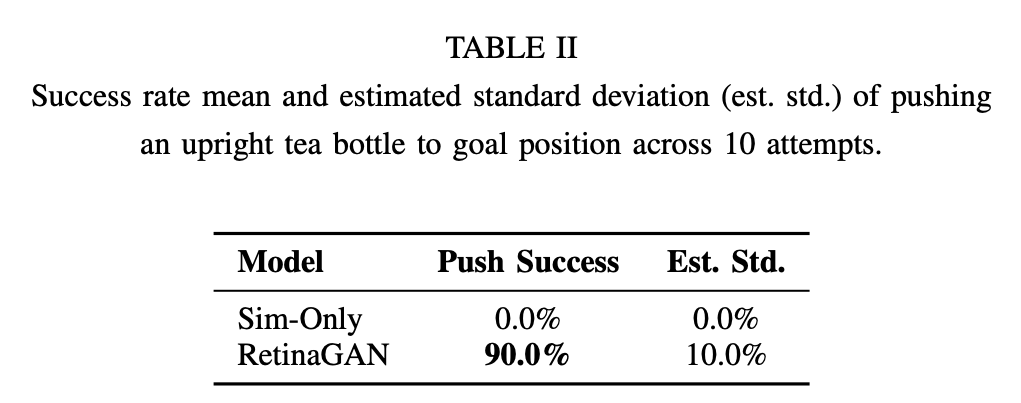
Evaluation results are displayed in Table II. We train a Q2-Opt policy to perform the pushing task in simulation only and achieve 90% sim success. When deploying the sim-only RL policy to real, we get 0% success, revealing a large sim-to-real gap. By applying RetinaGAN to the RL training data, we create a policy achieving 90% success, demonstrating strong transfer and understanding of the real domain.
C. Imitation Learning: Door Opening
We investigate RetinaGAN with a mis-matched object detector (trained on recycling objects) on an door opening task using a supervised learning form of behavioral cloning and imitation learning (IL). This task is set in a dramatically different visual domain, policy learning framework and algorithm, and neural network architecture. It involves a fixed, extended robot arm with a policy controlling the wheels of the robot base to open the doors of, and enter, conference rooms (Fig. 7).
The supervised learning policy is represented by a ResNet-FiLM architecture with 18 layers

With the door opening task, we explore how our domain adapation method performs in an entirely novel domain, training method, and action space, with a relatively low amount of real data (1,500 real demonstrations). We train the RetinaGAN model using the same object detector trained on recycling objects. This demonstrates the capacity to re-use labeled robot bounding box data across environments, eliminating further human labeling effort. Within door opening images, the perception model produces confident detections only for the the robot arm, but we hypothesize that structures like door frames could be maintained by consistency in low-probability prediction regimes.
Compared to baselines without consistency loss, RetinaGAN strongly preserves room structures and door locations, while baseline methods lose this consistency (see Appendix). This semantic inconsistency in GAN baselines presents a safety risk in real world deployment, so we did not attempt evaluations with these models.
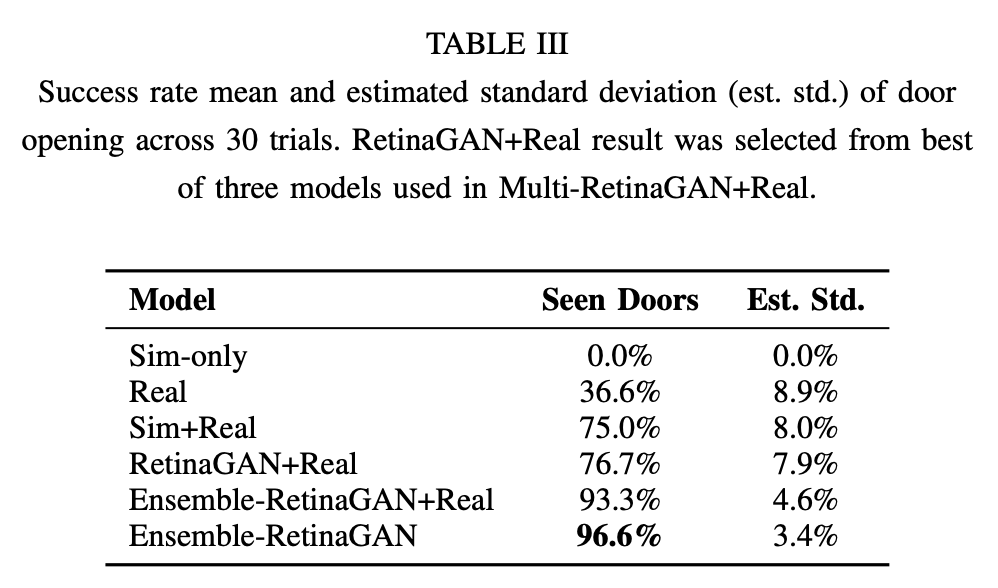
We then evaluate IL models trained with different data sources and domain adaptors, and displayed the results in Table III. An IL model trained on demonstrations in simulation and evaluated in simulation achieves 98% success. The same model fails in real with no success cases - showing a large sim-to-real gap.
By mixing real world demonstrations in IL model training, we achieve 75% success on conference room doors seen in training time. We achieve a comparable success rate, 76.7%, when applying RetinaGAN.
By training on data from three separate RetinaGAN models with different random seeds and consistency loss weights (called Ensemble-RetinaGAN), we are able to achieve 93.3% success rate. In the low data regime, RetinaGAN can oscillate between various reconstructed semantics and ambiguity in lighting and colors as shown in Fig. 7. We hypothesize that mixing data from multiple GANs adds diversity and robustness, aiding in generalization. Finally, we attempt Ensemble-RetinaGAN without any real data for training the IL model. We achieve 96.6%, within margin of error of the Ensemble-RetinaGAN+Real result.
VI. Conclusions
RetinaGAN is an object-aware sim-to-real adaptation technique which transfers robustly across environments and tasks, even with limited real data. We evaluate on three tasks and show 80% success on instance grasping, a 12 percentage-point improvement upon baselines. Further extensions may look into pixel-level perception consistency or other modalities like depth. Another direction of work in task and domain-agnostic transfer could extend RetinaGAN to perform well in a visual environment unseen at training time.
Appendix
A. Door Opening Figure
See Fig. 8 for example of semantic structure distortions when training the door opening task with CycleGAN.

B. Perception Model Training
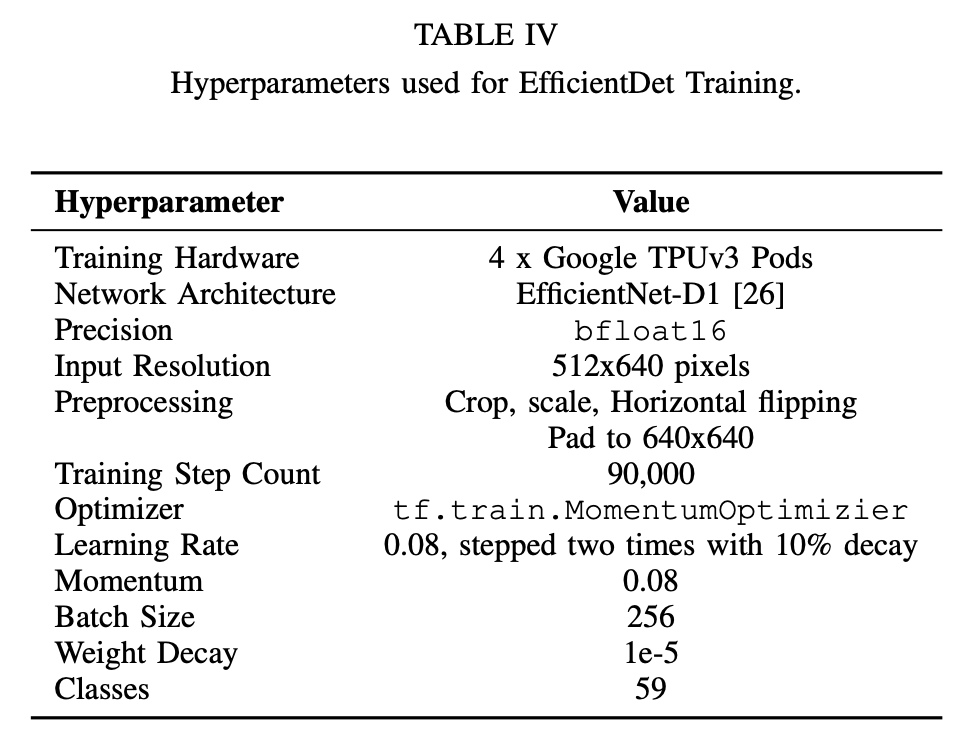
Hyperparameters used in object detection model training are listed in Table IV. We use default augmentation parameters from
C. RetinaGAN Model Training
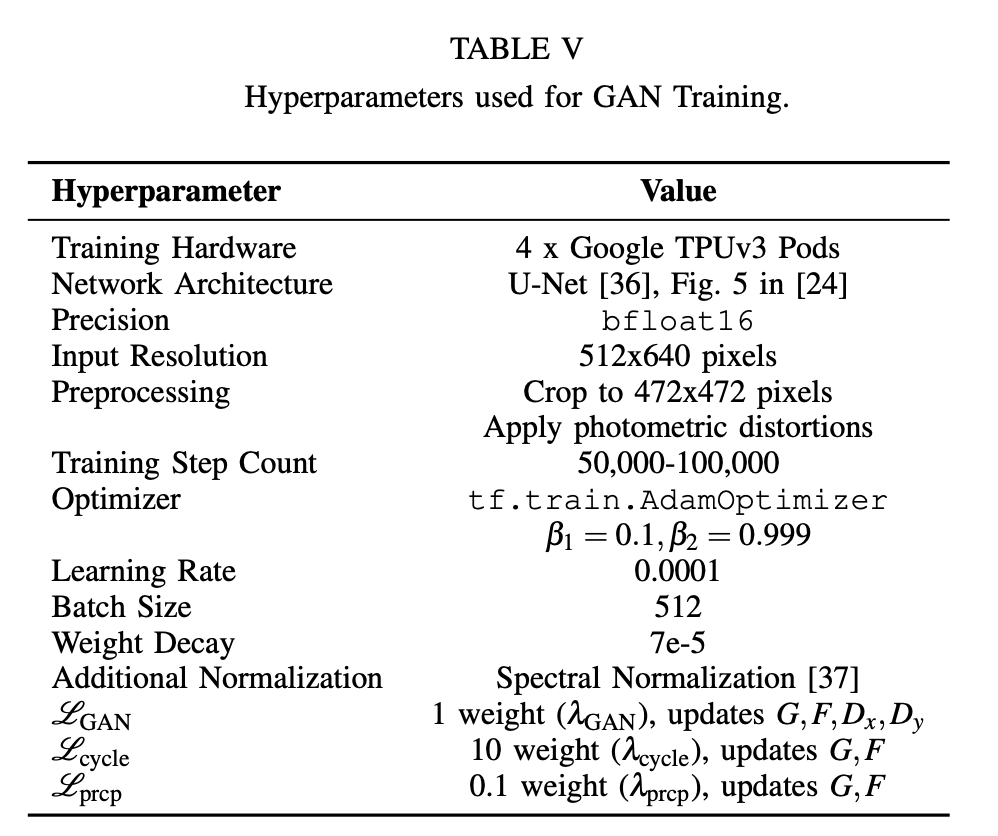
We train RetinaGAN with similar parameters to those described in Appendix A of
D. Q2-Opt RL Model Training
We use the Q2R-Opt
When using the full real dataset, we sample each minibatch from simulation episodes with a 50% weight and real episodes with a 50% weight. With the restricted 10K episode dataset, we sample from simulation with 20% weight and real with 80% weight, as to not overfit on the smaller real dataset. We did not tune these ratios, as in prior experiments, we found that careful tuning was not required.
E. ResNet-FiLM IL Model Training
We train IL with the ResNet-FiLM
F. Evaluation
For grasping, we evaluate with the station setup in Fig. 9. Each setup is replicated three times (with potentially different object brands/instances, but the same classes), and one robot positioned in front of each bin. We target the robot to only grasp the cup, can, and bottle, for a total of eighteen grasps. This is repeated five times for ninety total grasps.

For pushing, we evaluate with a single Ito En Green Tea Bottle filled 25% full of water.
For door opening, we evaluate on three real world conference room doors. Two doors swing rightwards and one door swings leftwards. The episode is judged as successful if the robot autonomously pushes the door open and the robot base enters the room.